As cloud services continue to grow, Ops (Operations) teams of those service providers face a surging burden. The factors contributing to this may include highly interwinded internal systems, mission-critical workloads requiring high levels of reliability, and demands for optimizing the operational costs of data centers.
This is exactly what Microsoft faces. With 60+ Azure regions globally, 300+ data centers, and millions of servers, Microsoft provides a multitude of services. Managing such a vast array of services while adapting to complex systems, enhancing service reliability, and reducing operational costs is a formidable task.
To address these obstacles, Microsoft has been leveraging artificial intelligence (AI) technology to streamline operations — an approach commonly known as AIOps. The tasks handled by AIOps are diverse, but they can be broadly categorized into two main areas:
- Incident Management: Response to incidents in a timely manner, minimizing the impact on users.
- Resource Management: Efficiently managing resources to ensure optimal service availability and performance while minimizing operational costs.
In this article series titled “Inside Azure AIOps”, I will walk you through how Microsoft plays their AIOps cards right to wrestle with the challenges of incident and resource management. Due to the high volume content, I will only focus on the introductory aspects in this first article, covering the basics of AIOps. The remaining topics will be explored in subsequent articles as follows:
- Inside Azure AIOps #1: Introduction
- Inside Azure AIOps #2: Incident Management
- Inside Azure AIOps #3: Resource Management
What is AIOps? Link to heading
Artificial Intelligence for IT Operations (AIOps) refers to the practice of leveraging AI technologies, notably Machine Learning (ML) algorithms and statistical testing, to improve IT operations.
The goal of AIOps is to maximize system availability and performance while minimizing operational costs. To achieve this, AIOps focuses on improving operations from a number of perspectives including:
- Automated Operations: Eliminating manual, repetitive, and error-prone tasks by automating them with data engineering and ML models. This allows Ops teams to focus on more valuable tasks.
- Proactive Operations: Leveraging AI techniques to predict potential issues before they occur, enabling proactive measures to be taken. This approach helps to minimize the impact of incidents on users.
- Observable Operations: Enhancing the observability of systems by collecting and analyzing data from various sources. This allows Ops teams to gain insights into system behavior and performance, facilitating informed decision-making.
The Journey of Ops Link to heading
It is said that the term AIOps was first coined in a Gartner report published in 20161, when the effectiveness of AI technologies (specifically DNNs) had been gradually gaining recognition, marked by the historical win of AlphaGo against a world-renowned Go player2, and their industurial implementation began to advance significantly.
Meanwhile, the late 2010s were marked by the widespread adoption of DevOps. The following illustration shows the trajectory of DevOps on Gartner’s Hype Cycle3. By 2016, when the concept of AIOps was born, DevOps had already passed the peak of inflated expectations and had entered a phase of steady implementation.
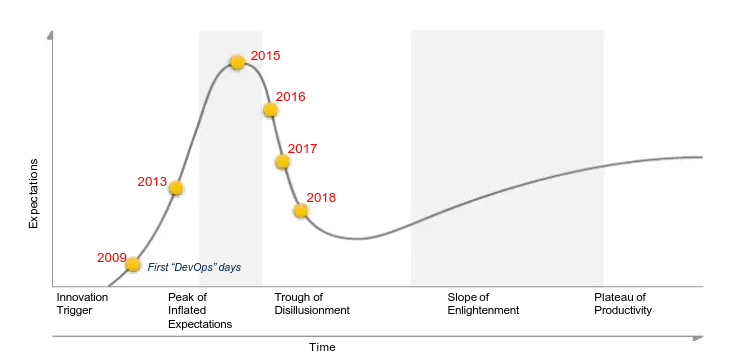
Transition of DevOps on the Hype Cycle (2009 - 2018)
Additionally, this period saw growing attention towards SRE (Site Reliability Engineering). SRE, an approach and set of practices designed to operate highly reliable production systems, originated from an initiative started by Google in 2003. For instance, the first international USENIX conference on SRE (SREcon) was held in 20144, and Microsoft has been presenting at SREcon since 2016.
Considering that DevOps and SRE also aim (at least partly) to improve operations, AIOps can be seen as a natural extension of these practices. AIOps enhances the automation and continuous feedback loop fostered by DevOps and SRE through AI technologies, improving the scope, accuracy, and degree of automation. In other words, AIOps can be viewed as the AI-driven completion of the missing pieces in DevOps and SRE.
The critical insight from this perspective is that AIOps is neither a dramatic paradigm shift that will revolutionize all existing IT operations nor a silver bullet that will solve every problem. It is essential to see AIOps as built upon the foundation of DevOps and SRE and to introduce it progressively.
Rediscovering AI x Ops Link to heading
One more point that needs to be clarified is that the improvement of Ops using AI technology is not a recent endeavor.
For instance, Support Vector Machines (SVMs), ML models that gained significant attention before the deep neural networks (DNNs) era, have been studied for fault detection since long ago5.
So, what differentiates earlier efforts from AIOps?
The phenomenon of rediscovering concepts is universal. In Japanese elementary schools, for example, we study a subject called “Koku-go (国語)”, which means the national language in the literal sense. While the Japanese language has been used among people for centuries, the term ‘Kokugo’ was actually coined in the late 1800s, when Japan was emerging from its period of isolation and aiming for modernization. The leaders at the time conceptualized ‘Koku-go’ with the purpose of unifying the entire nation. They believed that explicitly naming the language that people were speaking as a term related to national identity and teaching it would enhance national cohesion.
As such, the same concept can serve different roles depending on its label and and context. AIOps is no exception, in the sense that we expect different settings and outcomes for AIOps as compared to the prior initiatives, such as:
- Adaptation to Large-Scale Environments / Big Data: As IT systems grow increasingly complex over time, automation in operations now often involves handling large-scale data. As Gartner defines AIOps as a combination of big data and ML1, this clearly sets AIOps apart from past methods. AIOps is designed to meet the needs for operational improvements in such complex and huge environments.
- Use of Deep Neural Networks: The advent of Deep Neural Networks (DNNs) and Large Language Models (LLMs) has spurred numerous paradigm shifts in the realm of AI. Many studies and outcomes under the AIOps banner incorporate these latest methods, suggesting that “DNN/LLM for IT Operations” might even be a more fitting moniker. AIOps often explores the applicability of these cutting-edge AI technologies.
- User-Centered Design: The emergence of LLMs has introduced natural language as a new tool for machine-human communication. Furthermore, incorporating Human-in-the-Loop design to address hallucinations has become a best practice. This shift implies increased focus on the interaction between systems and humans. Consequently, elements of Human-Computer Interaction (HCI) are frequently considered in the system design of AIOps.
Microsoft and AIOps Link to heading
Microsoft is one of the leading organizations in the AIOps field, both academically and within the industry, having worked on ML-based operational improvements even before the birth of “AIOps”. Here are a few examples:
- In 2005: A method using a naive Bayes classifier to detect faults in web applications and identify the locations of these faults6.
- In 2010: A method that probabilistically classifies failures in peer-to-peer online storage systems to decrease network throughput across the system7.
- In 2012: A method based on hierarchical clustering to categorize crash types using call stacks from Windows Error Reporting (WER) crash reports8.
Folloing this legacy, Azure’s service teams and Microsoft Research (MSR) have been collaborating on advanced initiatives and sharing their findings within the academic community. These papers are featured in many prestigious journals and conferences, including ICSE, ESEC/FSE, OSDI, and NSDI.
The following resources provide insights into how Microsoft integrates AIOps within its services and wrestles with various challenges:
- Cloud Intelligence/AIOps – Infusing AI into Cloud Computing Systems - Microsoft Research
- Research talk: Cloud Intelligence/AIOps – Infusing AI into cloud computing - YouTube
- Advancing Azure service quality with artificial intelligence: AIOps | Microsoft Azure Blog
- AIOps: Real-World Challenges and Research Innovations - Microsoft Research
- AIOps - Microsoft Research
AIOps for Azure Users Link to heading
While the focus of this article is on AIOps from the perspective of operating Azure, it’s worth noting that users who build services on the Azure platform can also take advantages of AIOps.
For instance, in the context of fault detection, users can either opt in the managed offerings in Azure Monitor or harness Azure ML services to build their own AIOps pipeline with the help of Azure Monitor log ingestion capabilities.
AIOps and machine learning in Azure Monitor - Azure Monitor | Microsoft Learn
For the managed approach, features such as Metric Alerts with Dynamic Thresholds and Smart Detection in Application Insights are quick and easy to try out. Recently, a new monitoring feature called VM watch has been introduced in Public Preview, which allows to adaptively assess VM health based on various system metrics.
In the context of resource management, Azure Advisor’s Cost Optimization can recommend unnecessary resources. However, currently, Advisor’s recommendations are rule-based (expressed as expert system rules derived from Microsoft’s domain knowledge) rather than adaptively learning from the subscription environment.
My Thoughts on Reading Papers Link to heading
Finally, I would like to share a few thoughts after skimming through numerous papers on AIOps published by Microsoft Research, highlighting the common characteristics of Microsoft’s AIOps research:
Leveraging Existing Assets Link to heading
Implementing AIOps requires setting up monitoring systems, data processing pipelines (data infrastructure), platforms for training and inferring ML models, incident management systems, and an overall framework to seamlessly integrate these components. Microsoft effectively utilizes its extensive digital assets, accumulated over years of service and data center operations, to facilitate the adoption of AIOps.
Thorough Preliminary Research Link to heading
The famous performance tuning quote, “Measure. Don’t tune for speed until you’ve measured”9, underscores the importance of understanding the optimization target before taking action. This principle can be applied to almost any field, including AIOps.
Microsoft appears to grasp this discipline well. This is evident in their dedicated preliminary research efforts to identify pain points within operations teams, as demonstrated by the following empirical studies.
- Characterizing Cloud Computing Hardware Reliability - Microsoft Research
- Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications - Microsoft Research
- Gray Failure: The Achilles’ Heel of Cloud-Scale Systems - Microsoft Research
- Resource Central: Understanding and Predicting Workloads for Improved Resource Management in Large Cloud Platforms - Microsoft Research
- What bugs cause production cloud incidents? - Microsoft Research
- An Empirical Investigation of Incident Triage for Online Service Systems - Microsoft Research
- How to Fight Production Incidents? An Empirical Study on a Large-scale Cloud Service - Microsoft Research
- An Empirical Study of Log Analysis at Microsoft - Microsoft Research
- Detection Is Better Than Cure: A Cloud Incidents Perspective - Microsoft Research
- Towards Cloud Efficiency with Large-scale Workload Characterization - Microsoft Research
Proper Problem Setting Link to heading
There is one memorable teaching from my lab’s professor back in university: Those who solve a problem well deserve credits, but the person who formulates the problem deserves more.
Problem formulation is a crucial step preceding solution design; if the problem is set incorrectly, no matter how advanced the technology used, the solution won’t be practical or useful.
For instance, BMI (Body Mass Index) is one indicator used to evaluate body composition. While BMI has a medical relevance correlating with obesity, no bodybuilder would rely solely on BMI for their training regimens. This is because BMI does not capture the impact of body composition (fat percentage, water content) on weight. Focusing solely on improving BMI won’t get you to the level of Chris Bumstead10; a different approach is required.
The point is, incorrectly setting the improvement metrics won’t yield the expected results. Microsoft is very mindful of this, carefully framing the problem and KPIs.
One case in point is the Annual Interruption Rate (AIR), a metric developed as part of efforts to improve the reliability of Azure VMs. AIR is defined as “the average number of downtime incidents per 100 virtual machines over one year”11.
The reason for creating this specific metric is due to Azure’s nature of hosting mission-critical systems. Common time-based metrics like MTTF, MTTD, and MTTR often underplay transient downtime that quickly recovers, meaning these are not suitable for applications where even a brief downtime has a major impact (e.g., databases requiring time-consuming integrity checks).
Through its focus on careful problem setting and appropriate KPI design, Microsoft effectively realizes improvements in its AIOps initiatives.
Conclusion Link to heading
In this article, we focused on what AIOps is and gave an overview. If you take away just two things from this article, let it be these:
- AIOps is an AI-driven operational improvement practice built on existing approaches like DevOps and SRE.
- Microsoft is making significant strides in the AIOps domain.
In the following articles, we will delve into specific examples of how Microsoft/Azure are addressing incident management and resource management. I hope you will read those as well.
- Inside Azure AIOps #1: Introduction
- Inside Azure AIOps #2: Incident Management
- Inside Azure AIOps #3: Resource Management
Definition of AIOps (Artificial Intelligence for IT Operations) - IT Glossary | Gartner ↩︎ ↩︎
Fuqing, Yuan. “Failure diagnostics using support vector machine ↩︎
Combining Visualization and Statistical Analysis to Improve Operator Confidence and Efficiency for Failure Detection and Localization - Microsoft Research ↩︎
Protector: A Probabilistic Failure Detector for Cost-effective Peer-to-peer Storage - Microsoft Research ↩︎
ReBucket - A Method for Clustering Duplicate Crash Reports based on Call Stack Similarity - Microsoft Research ↩︎
[1910.12200] Annual Interruption Rate as a KPI, its measurement and comparison ↩︎